概述
Impala可以直接在存储在HDFS,HBase或Amazon Simple Storage Service(S3)中的Apache Hadoop数据上提供快速,交互式的SQL查询。 除了使用相同的统一存储平台,Impala和Apache Hive一样还使用相同的元数据,SQL语法(Hive SQL),ODBC驱动程序和用户界面(Hue中的Impala查询UI)。
Impala是用于查询大数据的工具的补充。 Impala不会替代基于MapReduce的批处理框架,如Hive。 基于MapReduce的Hive和其他框架最适用于长时间运行的批处理作业,例如涉及批处理Extract,Transform和Load(ETL)类型作业的工作。
1 impala特点
1.1 优点
- 基于内存进行计算,能够对PB级别的数据进行实时交互查询、分析
- C ++ 编写,LLVM(C++的一种编译器)统一编译,效率高
- 支持Data local 效率高
- 兼容HiveSQL
- 具有数据仓库的特性,可对hive数据直接做数据分析
- 支持列式存储(可以和hbase整合)
- 支持JDBC/ODBC远程访问
1.2 缺点
- 对内存依赖大
- 完全依赖于hive
- 实践过程中 分区超过1w 性能严重下下降
- 稳定性不如hive
2 体系架构

Impala的系统架构如上图所示,Impala使用了Hive的SQL接口(包括SELECT、INSERT、JOIN等操作),表的元数据信息存储在Hive Metastore中。StateStore是Impala的一个子服务,用于监控集群中各个节点的健康状况,提供节点注册、错误检测等功能;Impala在每个节点运行了一个后台服务Impalad,用于响应外部请求,并完成实际的查询处理。Impalad主要包含Query Planner、Query Coordinator和Query Exec Engine三个模块。Query Planner接收来自SQL APP和ODBC的查询,然后将查询转换为许多子查询,Query Coordinator将这些子查询分发到各个节点上,由各个节点上的Query Exec Engine负责子查询的执行,然后返回子查询的结果,这些中间结果经过聚集之后最终返回给用户。
3 安装方式
3.1 使用cloudera manager 进行安装
3.2 手动安装
4 核心组件
4.1 Statestore Daemon
该进程负责搜集集群中Impalad进程节点的健康状况,它通过创建多个线程来处理Impalad的注册订阅,并与各节点保持心跳连接,不断地将健康状况的结果转发给所有的Impalad进程节点。一个Impala集群只需一个statestored进程节点,当某一节点不可用时,该进程负责将这一信息传递给所有的Impalad进程节点,再有新的查询时不会把请求发送到不可用的节点上。
4.2 Catalog Daemon
Impala目录服务组件将Impala SQL语句产生的元数据更改通知到群集中的所有DataNodes上。避免了通过Impala发出的SQL语句执行时产生的元数据更改,需要发出REFRESH和INVALIDATE METADATA语句才能生效。当您通过Hive创建表,加载数据等时,您需要在Impala节点上执行REFRESH或INVALIDATE METADATA,然后才能执行查询。
4.3 Impala Daemon
它是运行在集群每个节点上的守护进程,是Impala的核心组件,在每个节点上这个进程的名称为Impalad。该进程负责读写数据文件;接受来自Impala-shell、Hue、JDBC、ODBC等客户端的查询请求(接收查询请求的Impalad为Coordinator),Coordinator通过JNI调用java前端解释SQL查询语句,生成查询计划树,再通过调度器把执行计划分发给具有相应数据的其它节点分布式并行执行,并将各节点的查询结果返回给中心协调者节点Coordinator,再由该节点返回给客户端。同时Impalad会与State Store保持通信,以了解其他节点的健康状况和负载。
4.4 Impala Shell
提供给用户查询使用的命令行交互工具,供使用者发起数据查询或管理任务,同时Impala还提供了Hue、JDBC、ODBC等使用接口。
5 impala CDH优化
- impala daemon 内存限制
- StateStore 工作线程数
6 impala-shell 用法
-h (--help) 帮助 -v (--version) 查询版本信息-V(--verbose) 启用详细输出 --quiet 关闭详细输出 -p 显示执行计划 -i hostname(--impalad=hostname) 指定连接主机 格式hostname:port 默认端口21000 -r(--refresh_after_connect)刷新所有元数据 -q query(--query=query) 从命令行执行查询,不进入impala-shell -d default_db(--database=default_db) 指定数据库 -B(--delimited)去格式化输出 --output_delimiter=character 指定分隔符 --print_header 打印列名 -f query_file(--query_file=query_file)执行查询文件,以分号分隔 -o filename(--output_file filename) 结果输出到指定文件 -c 查询执行失败时继续执行 -k(--kerberos) 使用kerberos安全加密方式运行impala-shell -l 启用LDAP认证 -u 启用LDAP时,指定用户名Impala Shell 进入impala-shell后的特殊用法: help connect <hostname:port> 连接主机,默认端口21000 refresh <tablename> 增量刷新元数据库 invalidate metadata 全量刷新元数据库 explain <sql> 显示查询执行计划、步骤信息 set explain_level 设置显示级别( 0,1,2,3) shell <shell> 不退出impala-shell执行Linux命令 profile (查询完成后执行) 查询最近一次查询的底层信息7 impala监控管理
7.1 查看StateStore
7.2 查看Catalog
8 impala存储
8.1 文件类型
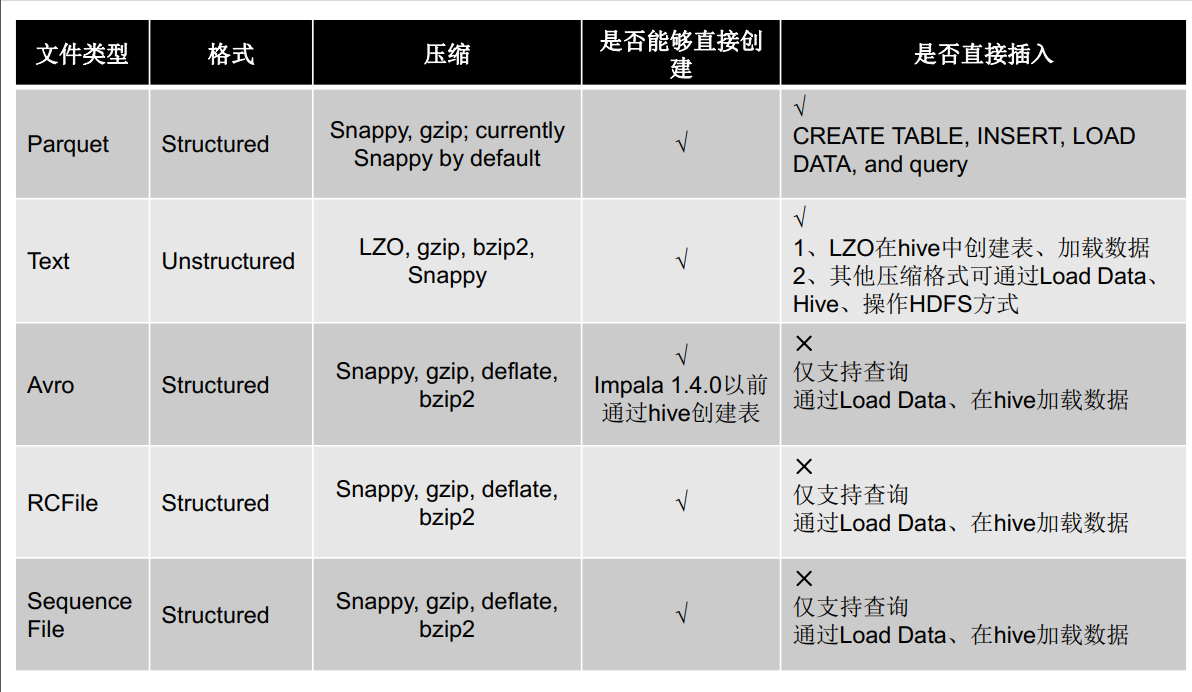
8.2 压缩方式

9 impala分区
9.1 创建分区方式
- partitioned by 创建表时,添加该字段指定分区列表
