写在之前
在程序设计里,我们经常需要将同为某个类型的一组数据元素作为一个整体来使用,需要创建这种元素组,用变量来记录它们或者传入函数等等等等,「线性表」就是这样一组元素的抽象,它是某类元素的集合并且记录着元素之间一种顺序关系,是最基本的数据结构之一,在实际程序中运用非常广泛,比如 Python 中的 list 和 tuple 都可以看作是线性表的实现。
基于各种实际操作等方面的综合考虑,我们提出了两种实现线性表的形式:「顺序表」和「链表」。
「顺序表」是将表中的元素顺序存放在一大块连续的存储区间里,所以在这里元素间的顺序是由它们的存储顺序来表示的。「链表」则是将表中元素存放在一系列的结点中(结点的存储位置可以是连续的,可以是不连续的,也就意味着它们可以存在任何内存未被占用的位置),这些结点通过连接构造起来,结点分为「数据域」和「指针域」。这次我们要学习的「单链表」就是「链表」的一种实现形式,「数据域」保存着作为表元素的数据项,「指针域」保存同一个表里的下一个结点的标识。
在正式说「单链表」之前,我先来说一下很多人在学习链表之初都傻傻分不清的两个东西:「头结点」和「头指针」。

「头结点」的设立是为了操作的统一和方便,是放在第一个元素的节点之前,它的数据域一般没有意义,并且它本身也不是链表必须要带的。那设立头节点的目的是什么呢?其实就是为了在某些时候可以更方便的对链表进行操作,有了头结点,我们在对第一个元素前插入或者删除结点的时候,它的操作与其它结点的操作就统一了。
「头指针」顾名思义,是指向链表第一个结点的指针,如果有头结点的话,那么就是指向头结点的指针。它是链表的必备元素且无论链表是否为空,头指针都不能为空,因为在访问链表的时候你总得知道它在什么位置,这样才能通过它的指针域找到下一个结点的位置,也就是说知道了头指针,整个链表的元素我们都是可以访问的,所以它必须要存在,这也就是我们常说的「标识」,这也就是为什么我们一般用头指针来表示链表。
单链表
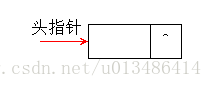
n 个结点链接成一个链表,这也就是平时书上所说的「链式存储结构」,因为这个链表中的每个结点中只包含一个指针域,所以又叫「单链表」。单链表正是通过每个结点的指针域将线性表的数据元素按其逻辑次序链接在一起。单链表的第一个结点的存储位置叫做「头指针」,最后一个结点的指针为「空」,一般用 “^” 表示。
上图是不带头结点的单链表,下面我们来看一下带头结点的单链表:
还有一种是空链表:
通过上面 3 个图我们发现无论单链表是否为空,是否有头结点,头指针都是存在的,这就很好的印证了之前我们所说的「头指针是链表的必备元素且无论链表是否为空,头指针都不能为空」。


为了方便后续的操作,我们一般会先定义一个简单的结点类:
class Node(object): def __init__(self,data): self.data = data self.next = None单链表的基本操作
首先我们先来创建一个链表类:
class LinkList(object): def __init__(self): self.head = Node(None) # 判断链表是否为空 def IsEmpty(self): p = self.head # 头指针 if p.next == None: print("List is Empty") return True return False # 打印链表 def PrintList(self): if self.IsEmpty(): return False p = self.head while p: print(p.data,end=' ') p = p.next1.创建单链表
创建单链表的过程其实就是一个动态生成链表的过程,说简单点就是从一个「空链表」开始,依次建立各个元素的结点,并把它们逐个插入链表,时间复杂度为 O(n):
def InitList(self,data): self.head = Node(data[0]) # 头结点 p = self.head # 头指针 for i in data[1:]: node = Node(i) p.next = node p = p.next下面我们来测试一下:
# test lst<
