引言
Bleve是Golang实现的一个全文检索库,类似Lucene之于Java。在这里通过阅读其代码,来学习如何使用及定制检索功能。也是为了通过阅读代码,学习在具体环境下Golang的一些使用方式。代码的路径在github上https://github.com/blevesearch/bleve。
Index Mapping是bleve的一个功能特性,用来控制每个类型的文档,文档内的每个字段,具体应该如何被分析、索引、存储,这部分与Lucence的设计思路相同。
1 IndexMapping的结构
Bleve通过IndexMapping及各成员结构,来控制如何对每种类型的Document,Document内的NestDocument,Document内的各Field进行分析、索引和存储。它本身是一个递归的结构,在DocumentMapping这一层可以进行任意深度的嵌套。
我们先整体看一下Index Mapping及其成员的从属关系。下图是我画的结构简图,很多成员并未在图上体现出来。本节的内容就是从左到右依次介绍每个结构类型的及其成员对应的物理意义。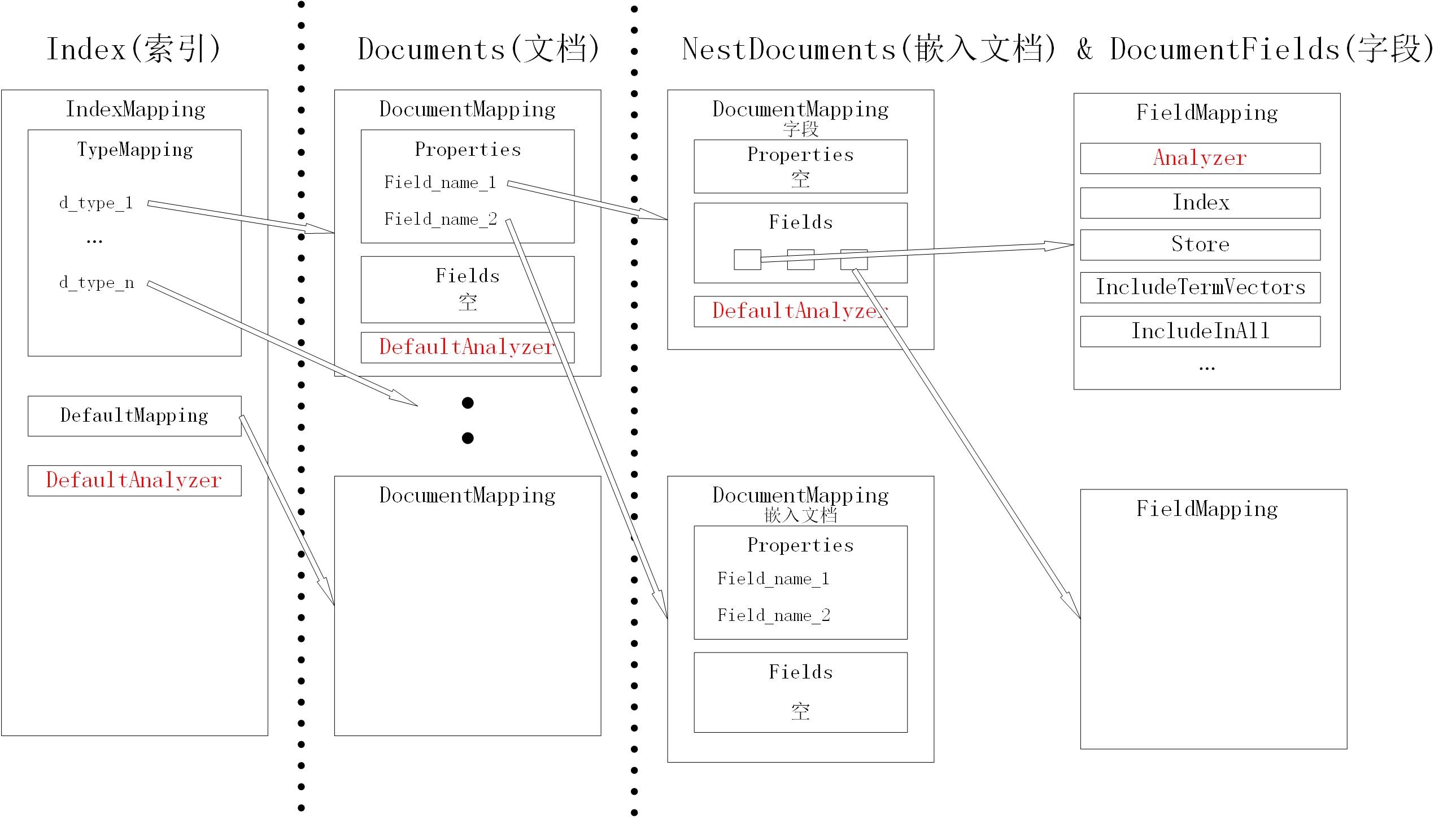
1.1 IndexMapping
从上一篇文章Bleve代码阅读(一)——新建索引我们知道,新建一个索引首先需要初始化一个IndexMapping结构。在示例代码中,这是通过函数bleve.NewIndexMapping()实现的,然后这个结构的指针被作为参数传递给bleve.New(index_path, index_mapping)。我们还知道,这个结构的内容被序列化后,存储在index文件里了。因此,这个结构与索引是一一对应的。
下面我们先看一下IndexMapping的定义代码,这个结构在上一篇文章也给出了。
type IndexMappingImpl struct { TypeMapping map[string]*DocumentMapping `json:"types,omitempty"` DefaultMapping *DocumentMapping `json:"default_mapping"` TypeField string `json:"type_field"` DefaultType string `json:"default_type"` DefaultAnalyzer string `json:"default_analyzer"` DefaultDateTimeParser string `json:"default_datetime_parser"` DefaultField string `json:"default_field"` StoreDynamic bool `json:"store_dynamic"` IndexDynamic bool `json:"index_dynamic"` DocValuesDynamic bool `json:"docvalues_dynamic,omitempty"` CustomAnalysis *customAnalysis `json:"analysis,omitempty"` cache *registry.Cache }上图最左边的矩形,就是代表了IndexMappingImpl这个结构,下面都以IndexMapping这个名称代替。TypeMapping也与图中的同名矩形对应,它是IndexMapping的一个成员。我们这里重点看一下这四个成员:
- TypeMapping:它是一个字符串到DocumentMapping指针的map。它的key是字符串,代表Document的类型。它的value是DocumentMapping的指针,用来定制该类型文档的索引方式。
- DefaultMapping:它是DocumentMapping的指针。当TypeMapping没有配置某类型文档的DocumentMapping时,则该类文档使用该默认的DocumentMapping。
- DefaultAnalyzer:默认的根节点Analyzer。由于每个DocumentMapping、每个DocumentField都可以配置自己的Analyzer,当处理某个Field时,优先使用最个性化的设置。找不到个性化的才使用默认的,一级一级往上找,直到这里。
- DefaultType:当一篇文档未提供分类时,就会使用DefaultType设置的类型名称,默认是“_default”,也可以修改。需要注意的是,一个文档时DefaultType不等于它就要使用DefaultMapping,可以在TypeMapping中为DefaultType设置个性化的索引方式。
1.2 DocumentMapping
从本文开头的图中可以看出,DocumentMapping是最多出现的一个结构,在文档、嵌入文档、字段这几个概念层次上都要用到。任何一个文本结构,都应该对应一个DocumentMapping,文本结构包括整个文档、文档内的嵌入文档、文档或嵌入文档内的字段。DocumentMapping的定义如下:
type DocumentMapping struct { Enabled bool `json:"enabled"` Dynamic bool `json:"dynamic"` Properties map[string]*DocumentMapping `json:"properties,omitempty"` Fields []*FieldMapping `json:"fields,omitempty"` DefaultAnalyzer string `json:"default_analyzer,omitempty"` // StructTagKey overrides "json" when looking for field names in struct tags StructTagKey string `json:"struct_tag_key,omitempty"` }1.2.1 文档
图中第二列最顶端的矩形,是一个对应原始文档的DocumentMapping。我们在这里重点关注以下几个成员:
- Enabled:如果为False,则整个文本结构不被index处理。
- Properties:一个map。key为文档的成员名,value是一个DocumentMapping的指针,该DocumentMapping对定义该成员的文本应该被如何处理。无论该成员是一个嵌入文档或是一个字段,都需要一个DocumentMapping与之对应。
- Fields:一个FieldMapping指针的切片。作为DocumentMapping的成员,如果当前DocumentMapping对应于一个文档或嵌入文档,则该字段为空。只有当前DocumentMapping对应一个字段,该成员才有可能非空。每个FieldMapping用来控制该字段应该被索引怎样分析、存储,一个字段可以有多个分析、存储方式。
- DefaultAnalyzer:当前文本结构的默认Analyzer。
1.2.2 嵌入文档
图中第三列下面的矩形,是一个对应嵌入文档的DocumentMapping。它所有成员的意义与对应文档的DocumentMapping相同。
1.2.3 字段
图中第三列顶端的矩形,是一个对应字段的DocumentMapping。它的成员的意义与对应文档的DocumentMapping略有不同,体现在以下两方面:
- Properties:当它是一个对应字段的DocumentMapping的成员时,为空。
- Fields:当它是一个对应字段的DocumentMapping的成员时,才可以不为空。它是一个FieldMapping指针的切片,定义了该字段应该被怎样处理,可以有多个处理方式。
1.3 FieldMapping
FieldMapping描述了一个具体的字段如何被放入索引。它一定包含于一个对应字段DocumentMapping,而不能直接被对应文档的DocumentMapping包含。FieldMapping的定义如下:
type FieldMapping struct { Name string `json:"name,omitempty"` Type string `json:"type,omitempty"` // Analyzer specifies the name of the analyzer to use for this field. If // Analyzer is empty, traverse t
