Storm 系列(五)—— Storm 编程模型详解
一、简介#
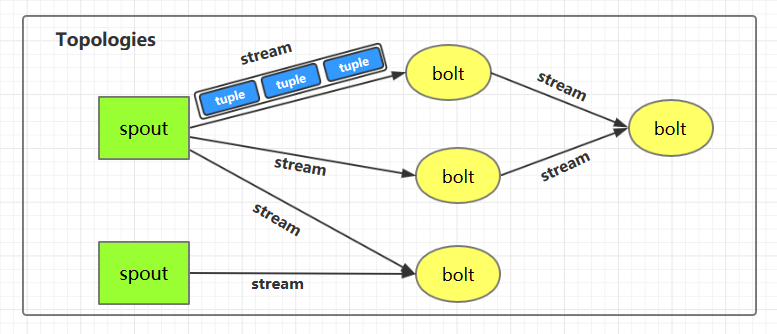
下图为 Strom 的运行流程图,在开发 Storm 流处理程序时,我们需要采用内置或自定义实现 spout(数据源) 和 bolt(处理单元),并通过 TopologyBuilder 将它们之间进行关联,形成 Topology。
二、IComponent接口#
IComponent 接口定义了 Topology 中所有组件 (spout/bolt) 的公共方法,自定义的 spout 或 bolt 必须直接或间接实现这个接口。
public interface IComponent extends Serializable { /** * 声明此拓扑的所有流的输出模式。 * @param declarer 这用于声明输出流 id,输出字段以及每个输出流是否是直接流(direct stream) */ void declareOutputFields(OutputFieldsDeclarer declarer); /** * 声明此组件的配置。 * */ Map<String, Object> getComponentConfiguration(); }三、Spout#
3.1 ISpout接口#
自定义的 spout 需要实现 ISpout 接口,它定义了 spout 的所有可用方法:
public interface ISpout extends Serializable { /** * 组件初始化时候被调用 * * @param conf ISpout 的配置 * @param context 应用上下文,可以通过其获取任务 ID 和组件 ID,输入和输出信息等。 * @param collector 用来发送 spout 中的 tuples,它是线程安全的,建议保存为此 spout 对象的实例变量 */ void open(Map conf, TopologyContext context, SpoutOutputCollector collector); /** * ISpout 将要被关闭的时候调用。但是其不一定会被执行,如果在集群环境中通过 kill -9 杀死进程时其就无法被执行。 */ void close(); /** * 当 ISpout 从停用状态激活时被调用 */ void activate(); /** * 当 ISpout 停用时候被调用 */ void deactivate(); /** * 这是一个核心方法,主要通过在此方法中调用 collector 将 tuples 发送给下一个接收器,这个方法必须是非阻塞的。 * nextTuple/ack/fail/是在同一个线程中执行的,所以不用考虑线程安全方面。当没有 tuples 发出时应该让 * nextTuple 休眠 (sleep) 一下,以免浪费 CPU。 */ void nextTuple(); /** * 通过 msgId 进行 tuples 处理成功的确认,被确认后的 tuples 不会再次被发送 */ void ack(Object msgId); /** * 通过 msgId 进行 tuples 处理失败的确认,被确认后的 tuples 会再次被发送进行处理 */ void fail(Object msgId); }3.2 BaseRichSpout抽象类#
通常情况下,我们实现自定义的 Spout 时不会直接去实现 ISpout 接口,而是继承