如何让excel文件读取变得更简单
今天给大家安利一款excel文件导入神器,easyexcel,官方地址:(https://github.com/alibaba/easyexcel)。
在官网文档中有介绍了其性能。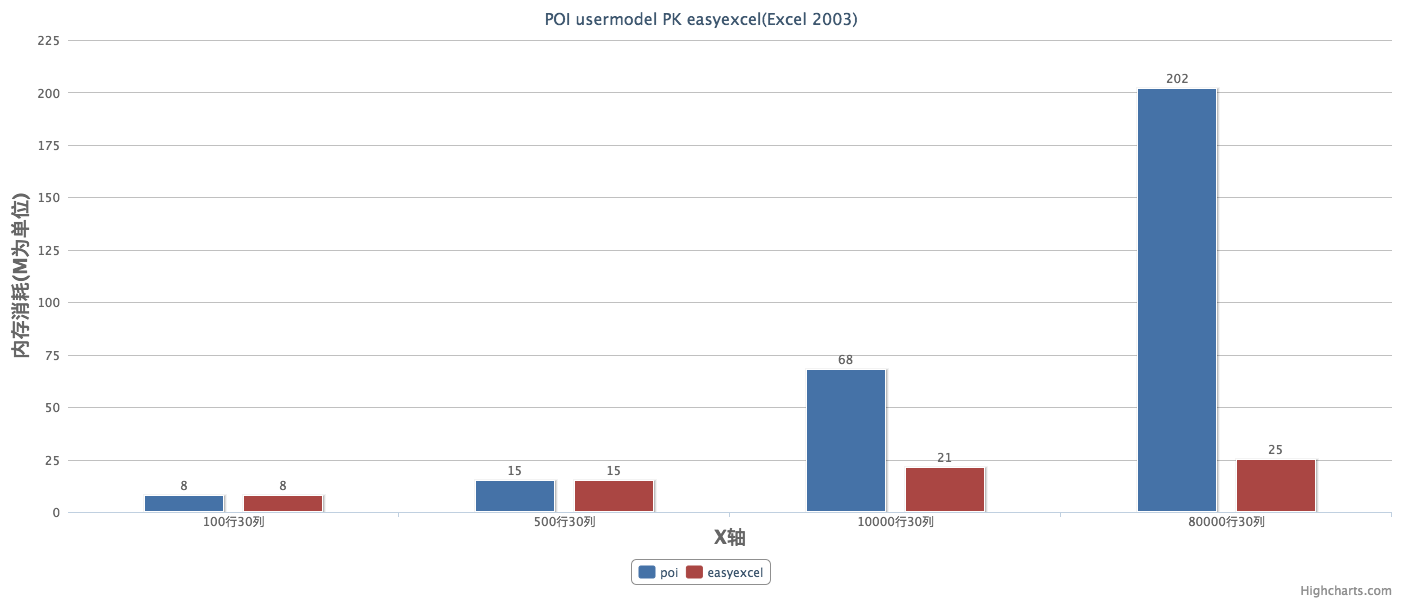



从上面的性能测试可以看出easyexcel在解析耗时上比poiuserModel模式弱了一些。主要原因是我内部采用了反射做模型字段映射,中间我也加了cache,但感觉这点差距可以接受的。但在内存消耗上差别就比较明显了,easyexcel在后面文件再增大,内存消耗几乎不会增加了。但poi userModel就不一样了,简直就要爆掉了。想想一个excel解析200M,同时有20个人再用估计一台机器就挂了。
如何使用呢
1、引入maven依赖
<dependency> <groupId>com.alibaba</groupId> <artifactId>easyexcel</artifactId> <version>2.0.5</version> </dependency>由于改jar包对poi进行了一些封装,因此需要注释掉项目引用的poi依赖,不然会有版本冲突。
2、创建接收excel数据的实体
@Data public class Person { @ExcelProperty(value = "姓名",index = 1) private String name; @ExcelProperty("性别") private String sex; @ExcelProperty("年龄") private int age; }@ExcelProperty 这个注解用于指定该属性对应excel文件中的哪一列数据。里面有两个属性,一个是value,另一个是index(从0开始),这里不建议 index 和 name 同时用,要么一个对象只用index,要么一个对象只用name去匹配。
3、增加person监听器
@Slf4j public class PersonListener extends AnalysisEventListener<Person> { /** * 每隔5条存储数据库,实际使用中可以3000条,然后清理list ,方便内存回收 */ private static final int BATCH_COUNT = 5; List<Person> list = new ArrayList(); @Override public void invoke(Person person, AnalysisContext analysisContext) { log.info("解析到一条数据:{}",person); if (list.size() >= BATCH_COUNT) { saveData(); list.clear(); } } @Override public void doAfterAllAnalysed(AnalysisContext analysisContext) { saveData(); log.info("所有数据解析完成!"); } @Override public void onException(Exception exception, AnalysisContext context) { log.error("解析失败,但是继续解析下一行", exception); } /** * 加上存储数据库 */ private void saveData(){ log.info("{}条数据,开始存储数据库!", list.size()); log.info("存储数据库成功!"); } }4、文件上传方法
@RestController @Slf4j