基于Prometheus和Grafana的监控平台 - 运维告警
通过前面几篇文章我们搭建好了监控环境并且监控了服务器、数据库、应用,运维人员可以实时了解当前被监控对象的运行情况,但是他们不可能时时坐在电脑边上盯着DashBoard,这就需要一个告警功能,当服务器或应用指标异常时发送告警,通过邮件或者短信的形式告诉运维人员及时处理。
今天我们就来聊聊 基于Prometheus和Grafana的监控平台的异常告警功能。
告警方式
Grafana
新版本的Grafana已经提供了告警配置,直接在dashboard监控panel中设置告警即可,但是我用过后发现其实并不灵活,不支持变量,而且好多下载的图表无法使用告警,所以我们不选择使用Grafana告警,而使用Alertmanager。
Alertmanager
相比于Grafana的图形化界面,Alertmanager需要依靠配置文件实现,配置稍显繁琐,但是胜在功能强大灵活。接下来我们就一步一步实现告警通知。
告警类型
Alertmanager告警主要使用以下两种:
- 邮件接收器 email_config
- Webhook接收器 webhook_config,会用post形式向配置的url地址发送如下格式的参数。
{ "version": "2", "status": "<resolved|firing>", "alerts": [{ "labels": < object > , "annotations": < object > , "startsAt": "<rfc3339>", "endsAt": "<rfc3339>" }] }这次主要使用邮件的方式进行告警。
#### 实现步骤
-
下载
从GitHub上下载最新版本的Alertmanager,将其上传解压到服务器上。
tar -zxvf alertmanager-0.19.0.linux-amd64.tar.gz - 配置Alertmanager
vi alertmanager.yml global: resolve_timeout: 5m smtp_smarthost: 'mail.163.com:25' #邮箱发送端口 smtp_from: 'xxx@163.com' smtp_auth_username: 'xxx@163.com' #邮箱账号 smtp_auth_password: 'xxxxxx' #邮箱密码 smtp_require_tls: false route: group_by: ['alertname'] group_wait: 10s # 最初即第一次等待多久时间发送一组警报的通知 group_interval: 10s # 在发送新警报前的等待时间 repeat_interval: 1h # 发送重复警报的周期 对于email配置中,此项不可以设置过低,否则将会由于邮件发送太多频繁,被smtp服务器拒绝 receiver: 'email' receivers: - name: 'email' email_configs: - to: 'xxx@xxx.com'修改完成后可以使用./amtool check-config alertmanager.yml校验文件是否正确。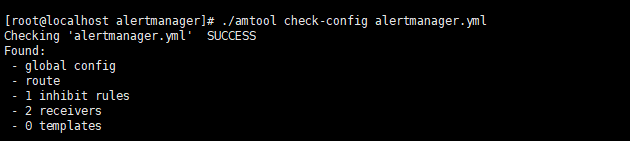
校验正确启动alertmanager。`nohup ./alertmanager &`。(第一次启动可以不使用nohup静默启动,方便后面查看日志) 我们只定义了一个路由,那就意味着所有由Prometheus产生的告警在发送到Alertmanager之后都会通过名为`email`的receiver接收。实际上,对于不同级别的告警,会有不同的处理方式,因此在route中,我们还可以定义更多的子Route。具体配置规则大家可以去百度进一步了解。-
配置Prometheus