一文彻底搞定谱聚类
Clustering 聚类
谱聚类
上文我们引入了是聚类,并介绍了第一种聚类算法K-means。今天,我们来介绍一种流行的聚类算法——谱聚类(Spectral Clustering),它的实现简单,而且效果往往好于传统的聚类算法,如k-means,但是其背后的原理涉及了很多重要而复杂的知识,如图论,矩阵分析等。别担心,今天小编就带你一举攻克这些难关,拿下谱聚类算法。
Q:什么是谱聚类?
A:谱聚类是最流行的聚类算法之一,它的实现简单,而且效果往往胜过传统的聚类算法,如K-means。它的主要思想是把所有数据看作空间中的点,这些点之间用带权重的边相连,距离较远的点之间的边权重较低,距离较近的点之间边权重较高,通过对所有数据点和边组成的图进行切图,让切图后不同子图间边权重和尽可能低,而子图内边权重和尽可能高来达到聚类的目的。
接下来我们先介绍图的基础知识以及图拉普拉斯,然后引入谱聚类算法,最后从图分割的角度来解释谱聚类算法。
图的概念
对于一个图G,我们通常用G(V,E)来表示它,其中V代表数据集合中的点{v1,v2,...vn},E代表边集(可以有边相连,也可以没有)。在接下来的内容中我们用到的都是带权重图(即两个顶点vi和vj之间的连边带有非负权重wij>0).由此可以得到一个图的加权邻接矩阵W=(Wij)i,j=1,...n。如果Wij=0代表两个顶点之间无边相连。无向图G中wij=wji,所以权重矩阵是对称的。
对于图中的任意一个点vi,定义它的度为与它相连的所有边的权重之和,即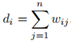 。度矩阵就是对角元素分别为每个点的度,非对角元素为0的矩阵。
。度矩阵就是对角元素分别为每个点的度,非对角元素为0的矩阵。
给定点的一个子集A属于V,定义A的补集为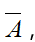 A的指示向量为
A的指示向量为 如果fi=1,则顶点vi在子集A中,否则为0。为了方便,在下文中,我们使用
如果fi=1,则顶点vi在子集A中,否则为0。为了方便,在下文中,我们使用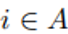 来表示顶点i在集合A中。对于两个不相交子集A,B属于V,我们定义
来表示顶点i在集合A中。对于两个不相交子集A,B属于V,我们定义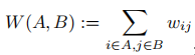 表示两个子集之间的权重和。
表示两个子集之间的权重和。
有两种度量V中子集A大小的方法:|A|表示A中顶点的个数,vol(A)表示A中顶点的度的和。
相似图
思考我们构建相似性图的目的是什么?是为了对点之间的局部邻域关系建模。那么根据我们所关注的邻域关系,相似性图的定义也可以不同,以下提到的图都经常在谱聚类中使用:
ε邻域图:将所有距离小于ε的点相连,由于有边相连的点之间都差不多,加权边不会包含关于图中数据点更多的关系,因此,这种图常常是无权重的;
k近邻图:将vi与它前k近的顶点相连,要注意,这种定义的图是有向图,因为k近邻关系并不是对称的(A是B的k近邻,而B不一定是A的k近邻)。我们可以通过两种方式将它变成无向图:一种是只要A是B的k近邻,AB之间就会连一条边;另一种是必须同时满足A,B是彼此的k近邻,才能在AB之间连一条边。在构建好图之后,在根据点的相似性给边赋权重;
全连接图:任意两点之间都连一条边,并根据两点之间的相似性给边赋权重。由于图必须能代表局部邻居关系,所以使用的相似性度量方法必须能对这种关系建模。比如,高斯相似性方程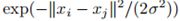 ,其中参数σ控制邻域的宽度(作用类似ε邻域图中的ε参数)。
,其中参数σ控制邻域的宽度(作用类似ε邻域图中的ε参数)。
图拉普拉斯矩阵及其基本性质
图拉普拉斯矩阵是谱聚类的主要工具,对这些矩阵的研究有一个专门的领域,叫做谱图理论,感兴趣的同学可以去了解下。在这章中我们定义不同的图拉普拉斯并介绍它们最重要的性质。
在接下来的介绍中,我们定义的图G是无向的,带权重的(权重矩阵为W),我们假定所有特征向量都是标准化的(如常向量C和aC是一样的),特征值是有序且可重复的,如果提到了前k个特征向量,就意味着这k个特征向量对应k个最小的特征值。D代表上文提到的度矩阵,W代表权重矩阵。
非规范化图拉普拉斯矩阵:
非规范化图拉普拉斯矩阵定义为L:D-W,它具有如下重要特性:
1. 对于任意特征向量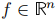 ,有:
,有:
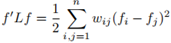 ;
;
证明:
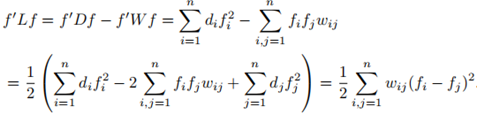
2. L是对称半正定的;
证明:D,W都是对称的,且特性1的证明表明L是半正定的;
3. L的最小特征值是0,对应的特征向量是单位向量;
4. L有n个非负的实值特征向量:
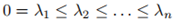
证明:由前三个特性可以直接得出;
注意非规范化图拉普拉斯矩阵以及它的特征向量,特征值可以被用在描述图的很多特性,其中在谱聚类中的一个重要性质如下:
