Web Scraper 翻页——利用 Link 选择器翻页 | 简易数据分析 14
这是简易数据分析系列的第 14 篇文章。
今天我们还来聊聊 Web Scraper 翻页的技巧。
这次的更新是受一位读者启发的,他当时想用 Web scraper 爬取一个分页器分页的网页,却发现我之前介绍的分页器翻页方法不管用。我研究了一下才发现我漏讲了一种很常见的翻页场景。
在 web scraper 翻页——分页器翻页的文章里,我们讲了如何利用 Element Click 选择器模拟鼠标点击分页器进行翻页,但是把同样的方法放在豆瓣 TOP 250 上,翻页到第二页时抓取窗口就会自动退出,一条数据都抓不到。
其实主要原因是我没有讲清楚这种方法的适用边界。
通过 Element Click 点击分页器翻页,只适用于网页没有刷新的情况,我在分页器那篇文章里举了蔡徐坤微博评论的例子,翻页时网页是没有刷新的:
仔细看下图,链接发生了变化,但是刷新按钮并没有变化,说明网页并没有刷新,只是内容变了

而在 豆瓣 TOP 250 的网页里,每次翻页都会重新加载网页:
仔细看下图,链接发生变化的同时网页刷新了,有很明显的 loading 转圈动画

其实这个原理从技术规范上很好解释:当一个 URL 链接是 # 字符后数据变化时,网页不会刷新;当链接其他部分变化时,网页会刷新。当然这个只是随口提一下,感兴趣的同学可以去这个链接研究一下,不感兴趣可以直接跳过。
1.创建 Sitemap
本篇文章就来讲解一下,如何利用 Web Scraper 抓取翻页时会刷新网页的分页器网站。
这次的网页我们选用最开始练手 Web Scraper 的网站——豆瓣电影 TOP250,换个姿势练习 Web Scraper 翻页技巧。
像这种类型的网站,我们要借助 Link 选择器来辅助我们翻页。Link 标签我们在上一节介绍过了,我们可以利用这个标签跳转网页,抓取另一个网页的数据。这里我们利用 Link 标签跳转到分页网站的下一页。
首先我们用 Link 选择器选择下一页按钮,具体的配置可以见下图:
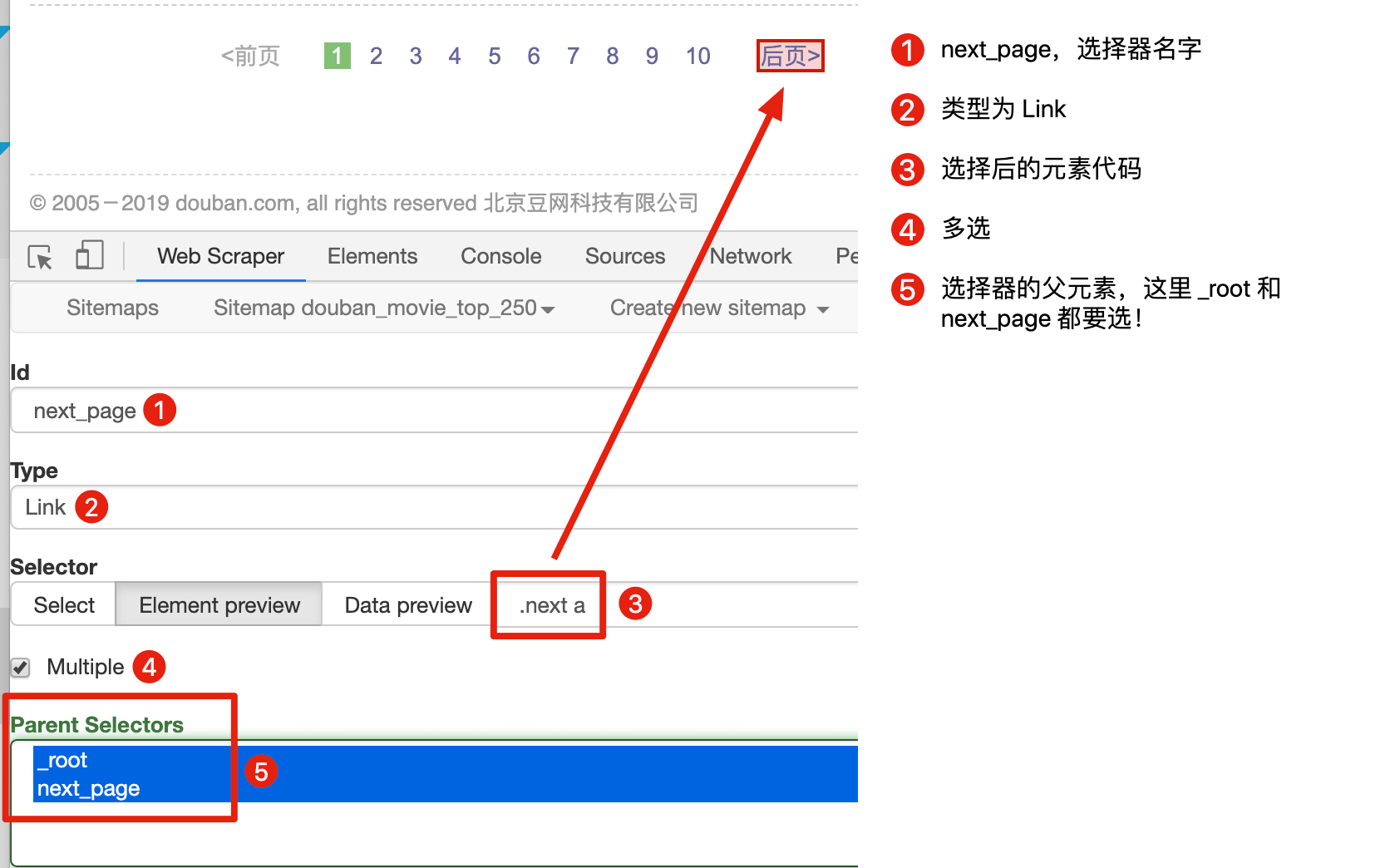
这里有一个比较特殊的地方:Parent Selectors ——父选择器。
之前我们都没有碰过这个选择框的内容,**next_page 这次要有两个父节点——_root 和 next_page**,键盘按 shift 再鼠标点选就可以多选了,先按我说的做,后面我会解释这样做的理由。
保存 next_page 选择器后,在它的同级下再创建 container 节点,用来抓取电影数据:

这里要注意:翻页选择器节点 next_page 和数据选择器节点 container 是同一级,两个节点的父节点都是两个:_root 和 next_page:

因为重点是 web scraper 翻页技巧,抓取的数据上我只简单的抓取标题和排名: